In my
previous blog post I was experimenting with some algorithms to detect and decode morse code from noisy RF band. Since the results looked promising I have spent some time implementing matched filter algorithm in FLDIGI. I also implemented a neural network decoder based on Self Organized Maps (SOM) algorithms.
I started by downloading fldigi-3.21.41 source code from W1HKJ
download page. Once I got the software to compile properly on my Linux system I studied the internals how CW detection & decoding really works in FLDIGI.
1) FLDIGI CW MODULE INTRODUCTION
Main modules are in CW.CXX and MORSE.CXX. After initialization the
cw:rx_process() function receives new audio data 512 samples on continuous basis (this block size is actually configured in sound.h - see
#define SCBLOCKSIZE ).
Once a block of data is received, there are some checks done if user has changed the low pass filter bandwidth. Then the algorithm creates a baseband signal by mixing with audio carrier frequency of selected signal. The next step is to run a low pass filter, demodulate by taking the magnitude of the signal and finally running the envelope through a moving average filter. There is also AGC (automatic gain control) function with fast attack and slow decay. A check is done if squelch is on and if signal exceeds squelch value (this is to reduce noise created errors). If the signal has upward trend the control gets passed to
handle_event() function and same is done with downward trend.
Handle_event() keeps track of "dits" and "dahs" and eventually returns decoded character using
morse::rx_lookup() function.
There is actually much more going on than the above simple explanation. The software keeps track of morse speed, automatic gain control, dit/dah ratio and various other parameters. Also, the user interface is updated - if you have signal scope on the signal amplitude value is updated between characters etc.
2) EXPERIMENTAL FEATURES ADDED
Matched Filter
I implemented
Matched Filter algorithm using a simple convolution method. The implementation is in MFILT.CXX and it has few key functions.
Mfilt::create_filter() calculates "dit" time based on current morse speed. It also allocates memory for 3 buffers for the convolution. Finally, it creates a convolution kernel - this is a "dit" long sine wave burst at selected CW frequency.
Mfilt::convolve() performs linear convolution with very straight forward calculation. It has not been speed optimized but seems to be fast enough on my desktop computer.
Mfilt::run() collects input samples until selected input buffer has been filled. Once enough samples are collected it will call the
convolve() function.
Compared to other FLDIGI filters this is a very straight forward filter and no speed optimization has been done. I am sure that the gurus who wrote FLDIGI filters could improve this a lot.
SOM (Self Organizing Map) decoding
Last year I spent some time trying to understand how to use
Self Organizing Map algorithm to decode noisy signals. I collected quite a lot of data from my Flexradio 3000 trying to cover multiple signals from different bands (40m, 20m, 17m) and from different stations with varying signal strengths and keying styles. The idea behind this work was to figure out if SOM algorithm would learn unsupervised how to decode morse code when presented a variety of signals as learning data.
Self Organizing Maps are different from other artificial neural networks as they use a neighborhood function to preserve topological properties of the input space. Like most artificial neural networks, SOMs operate in two modes:
training and mapping. Training builds the map using input examples. It
is a
competitive process, also called
vector quantization. Mapping automatically classifies a new input vector.
I used the
SOM Toolbox 2.0 from my alma mater. This excellent software package written for Matlab 5 did also work with
Octave after some tweaking.
I basically created one large morse learning dataset and then run SOM training algorithm to create 20 x 20, 10 x 10 and 7 x 7 rectangular neuron grids with morse characters clustered based on their topological properties. It was very interesting to see how morse code characters with similar properties ("E" = "dit" and "I" = "dit dit") automatically converged to nearby neuron cells.
I was first planning to implement this type of self learning algorithm as part of FLDIGI but realized soon that coding the entire SOM toolbox functions with C++ would be quite a large project.
After pondering this problem for a while I realized that the essence of the problem was perhaps not the learning part but using the "Best Matching Unit" algorithm against a known codebook. After all, morse code is well defined and every character should match to one codebook entry. The BMU algorithm basically iterates through all the nodes, calculates Euclidian distance between each node weigth vector and current input vector. The node with weight vector closest to input vector is tagged as the "best matching unit".
The Euclidian distance is given as:
where V is the current input vector and W is the weight vector.
I created the following "
find_winner()" function. It takes a buffer with detected "dit" and "dah" lengths and the duration of two dots as input parameters. It then computes the distance between codebook and input vector. The winner is the closest match with smallest distance. Since taking square root is computationally expensive function we simplify by calculating
Manhattan distance that works as well here:
const char *find_winner (float *inbuf, int twodots)
{
int i;
SOM_TABLE *som, *winner;
float diffsf = 999999999999.0;
float difference = 0.0;
float diff;
if ( normalize (inbuf, 7, twodots) == 0) return NULL;
winner = NULL;
for (som = som_table; som->chr != 0; som++) {
/* Compute the distance between codebook and input entry */
difference = 0.0;
for (i = 0; i < 7; i++) {
diff = (inbuf[i] - som->wgt[i]);
difference += diff * diff;
if (difference > diffsf) break;
}
/* If distance is smaller than previous distances */
if (difference < diffsf) {
winner = som;
diffsf = difference;
}
}
if (winner != NULL)
return winner->prt;
else
return NULL;
}
In order to normalize the durations of "dits" and "dahs" I used the following function:
int normalize(float *v, int n, int twodots)
{
float max = -99999999999999.9;
float min = 999999999999999.9;
int j;
/* find max and min values */
for (j=0; j<n; j++) {
if (v[j] > max) max = v[j];
if (v[j] < min) min = v[j];
}
/* all values 0 - no need to normalize or decode */
if (max == 0.0) return 0;
/* scale values between [0,1] -- if Max longer than 2 dots it was "dah" and should be 1.0, otherwise it was "dit" and should be 0.33 */
if (max > twodots)
for (j=0; j<n; j++) v[j] = v[j] / max;
else
for (j=0; j<n; j++) v[j] = 0.33 * v[j]/ max;
return (1);
}
Finally, I created a codebook that has normalized durations - "dah" is 1.0 and "dit is 0.33 following the standard morse code conventions.
struct SOM_TABLE {
char chr; /* The character(s) represented */
const char *prt; /* The printable representation of the character */
float wgt[7]; /* Dot-dash weight vector */
};
static SOM_TABLE som_table[] = {
/* Prosigns */
{'=', "<BT>", {1.0, 0.33, 0.33, 0.33, 1.0, 0, 0} }, // 0
{'~', "<AA>", { 0.33, 1.0, 0.33, 1.0, 0, 0, 0} }, // 1
{'%', "<AS>", { 0.33, 1.0, 0.33, 0.33, 0.33, 0, 0} }, // 2
{'+', "<AR>", { 0.33, 1.0, 0.33, 1.0, 0.33, 0, 0} }, // 3
{'>', "<SK>", { 0.33, 0.33, 0.33, 1.0, 0.33, 1.0, 0} }, // 4
{'<', "<KN>", {1.0, 0.33, 1.0, 1.0, 0.33, 0, 0} }, // 5
{'&', "<INT>", { 0.33, 0.33, 1.0, 0.33, 1.0, 0, 0} }, // 6
{'}', "<HM>", { 0.33, 0.33, 0.33, 0.33, 1.0, 1.0, 0} }, // 7
{'{', "<VE>", { 0.33, 0.33, 0.33, 1.0, 0.33, 0, 0} }, // 8
/* ASCII 7bit letters */
{'A', "A", { 0.33, 1.0, 0, 0, 0, 0, 0} },
{'B', "B", {1.0, 0.33, 0.33, 0.33, 0, 0, 0} },
{'C', "C", {1.0, 0.33, 1.0, 0.33, 0, 0, 0} },
{'D', "D", {1.0, 0.33, 0.33, 0, 0, 0, 0} },
{'E', "E", { 0.33, 0, 0, 0, 0, 0, 0} },
{'F', "F", { 0.33, 0.33, 1.0, 0.33, 0, 0, 0} },
{'G', "G", {1.0, 1.0, 0.33, 0, 0, 0, 0} },
{'H', "H", { 0.33, 0.33, 0.33, 0.33, 0, 0, 0} },
{'I', "I", { 0.33, 0.33, 0, 0, 0, 0, 0} },
{'J', "J", { 0.33, 1.0, 1.0, 1.0, 0, 0, 0} },
{'K', "K", {1.0, 0.33, 1.0, 0, 0, 0, 0} },
{'L', "L", { 0.33, 1.0, 0.33, 0.33, 0, 0, 0} },
{'M', "M", {1.0, 1.0, 0, 0, 0, 0, 0} },
{'N', "N", {1.0, 0.33, 0, 0, 0, 0, 0} },
{'O', "O", {1.0, 1.0, 1.0, 0, 0, 0, 0} },
{'P', "P", { 0.33, 1.0, 1.0, 0.33, 0, 0, 0} },
{'Q', "Q", {1.0, 1.0, 0.33, 1.0, 0, 0, 0} },
{'R', "R", { 0.33, 1.0, 0.33, 0, 0, 0, 0} },
{'S', "S", { 0.33, 0.33, 0.33, 0, 0, 0, 0} },
{'T', "T", {1.0, 0, 0, 0, 0, 0, 0} },
{'U', "U", { 0.33, 0.33, 1.0, 0, 0, 0, 0} },
{'V', "V", { 0.33, 0.33, 0.33, 1.0, 0, 0, 0} },
{'W', "W", { 0.33, 1.0, 1.0, 0, 0, 0, 0} },
{'X', "X", {1.0, 0.33, 0.33, 1.0, 0, 0, 0} },
{'Y', "Y", {1.0, 0.33, 1.0, 1.0, 0, 0, 0} },
{'Z', "Z", {1.0, 1.0, 0.33, 0.33, 0, 0, 0} },
/* Numerals */
{'0', "0", {1.0, 1.0, 1.0, 1.0, 1.0, 0, 0} },
{'1', "1", { 0.33, 1.0, 1.0, 1.0, 1.0, 0, 0} },
{'2', "2", { 0.33, 0.33, 1.0, 1.0, 1.0, 0, 0} },
{'3', "3", { 0.33, 0.33, 0.33, 1.0, 1.0, 0, 0} },
{'4', "4", { 0.33, 0.33, 0.33, 0.33, 1.0, 0, 0} },
{'5', "5", { 0.33, 0.33, 0.33, 0.33, 0.33, 0, 0} },
{'6', "6", {1.0, 0.33, 0.33, 0.33, 0.33, 0, 0} },
{'7', "7", {1.0, 1.0, 0.33, 0.33, 0.33, 0, 0} },
{'8', "8", {1.0, 1.0, 1.0, 0.33, 0.33, 0, 0} },
{'9', "9", {1.0, 1.0, 1.0, 1.0, 0.33, 0, 0} },
/* Punctuation */
{'\\', "\\", { 0.33, 1.0, 0.33, 0.33, 1.0, 0.33, 0} },
{'\'', "'", { 0.33, 1.0, 1.0, 1.0, 1.0, 0.33, 0} },
{'$', "$", { 0.33, 0.33, 0.33, 1.0, 0.33, 0.33,1.0} },
{'(', "(", {1.0, 0.33, 1.0, 1.0, 0.33, 0, 0} },
{')', ")", {1.0, 0.33, 1.0, 1.0, 0.33, 1.0, 0} },
{',', ",", {1.0, 1.0, 0.33, 0.33, 1.0, 1.0, 0} },
{'-', "-", {1.0, 0.33, 0.33, 0.33, 0.33, 1.0, 0} },
{'.', ".", { 0.33, 1.0, 0.33, 1.0, 0.33, 1.0, 0} },
{'/', "/", {1.0, 0.33, 0.33, 1.0, 0.33, 0, 0} },
{':', ":", {1.0, 1.0, 1.0, 0.33, 0.33, 0.33, 0} },
{';', ";", {1.0, 0.33, 1.0, 0.33, 1.0, 0.33, 0} },
{'?', "?", { 0.33, 0.33, 1.0, 1.0, 0.33, 0.33, 0} },
{'_', "_", { 0.33, 0.33, 1.0, 1.0, 0.33, 1.0, 0} },
{'@', "@", { 0.33, 1.0, 1.0, 0.33, 1.0, 0.33, 0} },
{'!', "!", {1.0, 0.33, 1.0, 0.33, 1.0, 1.0, 0} },
{0, NULL, {NULL}}
};
I implemented above SOM feature in FLDIGI to see if the morse decoding works any better than the token lookup based algorithm in MORSE.CXX.
It is hard to quantify the improvement dealing with real life noisy morse signals as there are so many variables. In order to compare the algorithms I decided to create a test bed where I can run a known audio file with known morse code content and use FLDIGI to decode the signals.
3) TEST RESULTS
To test these new features I created a very noisy morse signal using
morse.m by Rob, KL7NA. The text was "THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG - 1234567890". The noise level is 2 making it quite hard to hear the actual signal from the noise. As expected the original FLDIGI CW module has difficulties detecting the morse code. See figure 1 below.
 |
| Figure 1. FLDIGI - errors detecting morse code from noise |
Using the new features I implemented (Matched Filter and SOM) I run the same noisy signal. See figure 2. below - now the text is almost readable and the amount of errors has significantly reduced.
 |
| Figure 2. FLDIGI - with Matched Filter and SOM features enabled |
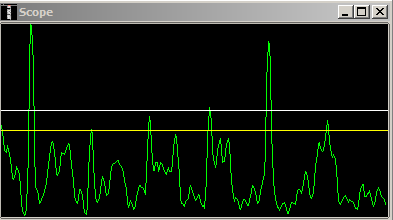
Looking at the FLDIGI signal scope below you can see the difference on noise level. Note that these were captured at different times so they represent different morse letters. Figure 3 is without matched filter and figure 4 has matched filter enabled. Reduction of noise is clearly visible.
 |
| Figure 3. Without Matched Filter |
 |
| Figure 4. With Matched Filter |
To enable testing Matched Filter I modified the FLDIGI Modems / CW / General configuration screen. I added a checkbox and a "Matched Filter length" slider that represents buffer length in 10ms units. So "227" in figure 5 below represents 2.27 second input buffer for the matched filter. The results improve the longer the buffer is set but this also causes longer latency between the received audio and decoded characters appearing on the screen. At 18 WPM morse speed 1...2 second delay seemed like a reasonable compromise. I set the range between 100ms and 3 seconds in the user interface. For longer messages such as bulletins even longer buffer could be applicable.
I am also using "Use Farnsworth timing" tick box to enable/disable SOM detection feature (I was lazy and did not want to create another tick box user interface). This enables to test SOM feature in real time and see if it makes any difference.
 |
| Figure 5. Modified FLDIGI configuration screen |
4) CONCLUSIONS
I implemented two new experimental features to FLDIGI software package, namely Matched Filter and Self Organizing Maps decoding. My objective was to improve FLDIGI morse code detection and decoding capabilities.
Based on above testing it seems that both detection and decoding capabilities improved compared to baseline algorithms in FLDIGI. However, the testing above was done with artificially generated noisy morse signal, not with real life audio from noisy RF bands. I am planning to run more tests to verify how well these features work with real life cases.
These two experimental features could potentially be beneficial in the following areas:
- Decoding morse signals with low signal-to-noise ratio such as in VHF / UHF / 50 Mhz bands - combined with PSK reporter type functionality we could get automatic alerts on band openings, such as Es or tropo, from FLDIGI
- Monitoring weak CW beacons
- Working with QRP stations
- Perhaps even working EME QSOs with smaller antennas
The software is alpha quality and not ready for broader distribution. Since I have only limited amount of time available I would like to collaborate with other hams who could help me to improve this software and hopefully make it ready for mainline FLDIGI distribution in future.
If you are able to compile FLDIGI from source tar files on Linux and you don't need any support to resolve problems I can send the tar file via email.
5) ACKNOWLEGEMENT
I would like to express my gratitude to David H Freese, W1HKJ for making FLDIGI available as open source software. This great software package is not only very useful piece of ham radio software but also a fantastic treasure trove of digital signal processing gems.
I would also like to thank Rob Frohne, KL7NA for making matched filter and many other algorithms publicly available for his students and providing great insights over multiple emails we have exchanged.
73 de Mauri, AG1LE





























{kind=link}